Finding Things: Image Parsing with Regions and Per-Exemplar Detectors
Joseph Tighe and Svetlana Lazebnik
Dept. of Computer Science, University of North Carolina at Chapel Hill
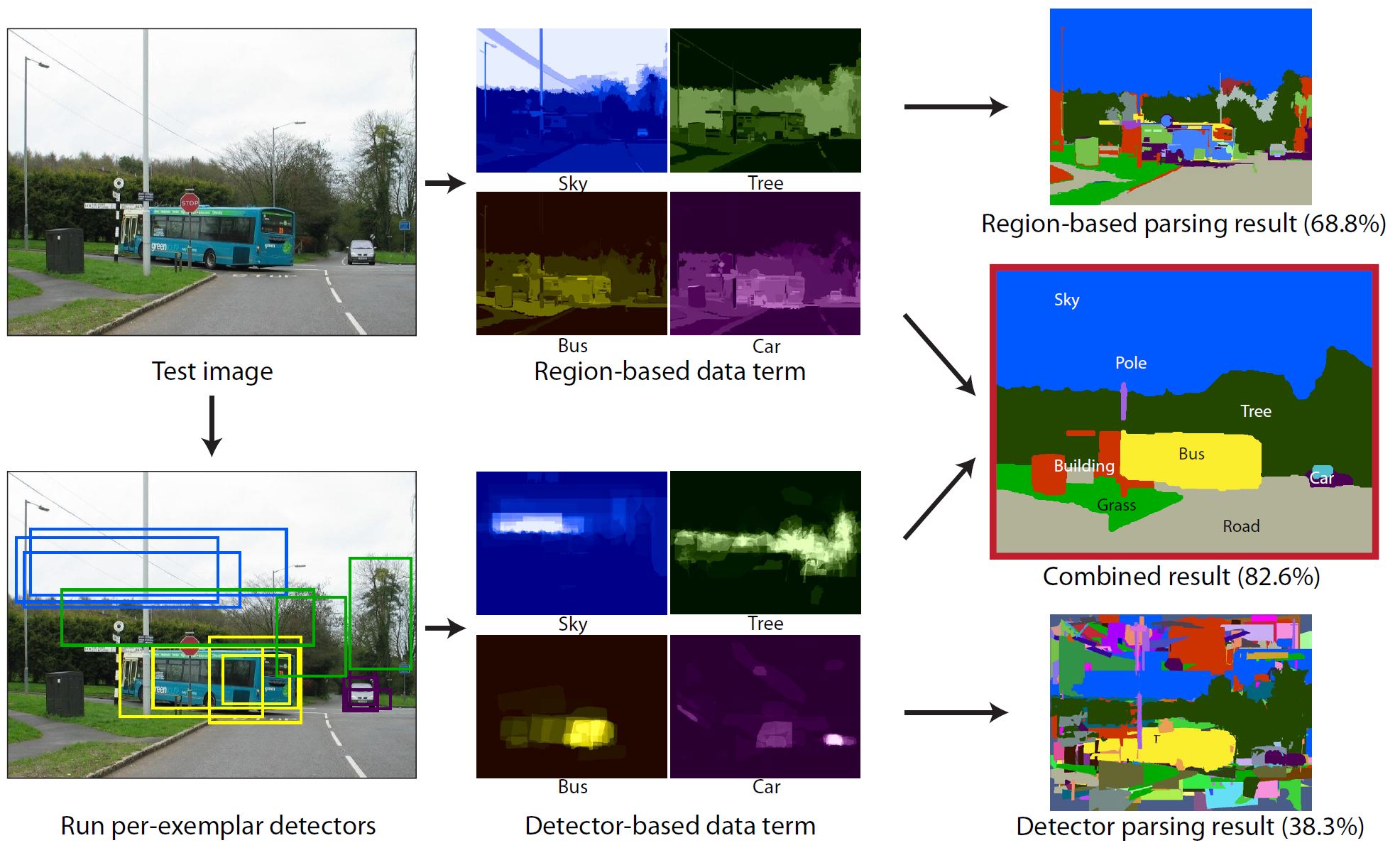
| Abstract: This paper presents a system for image parsing, or labeling each pixel in an image with its semantic category, aimed at achieving broad coverage across hundreds of object categories, many of them sparsely sampled. The system combines region-level features with per-exemplar sliding window detectors. Per-exemplar detectors are better suited for our parsing task than traditional bounding box detectors: they perform well on classes with little training data and high intra-class variation, and they allow object masks to be transferred into the test image for pixel-level segmentation. The proposed system achieves state-of-the-art accuracy on three challenging datasets, the largest of which contains 45,676 images and 232 labels. | |
| Please note that additional training data was used for CamVid than the results from other papers cited in this work. Specifically, the frames labelled at 15Hz were also included in the training set. We don't believe this extra training data has a significant impact but the comparison to other works is not strictly fair. | |
|
Citation: Joseph Tighe and Svetlana Lazebnik "Finding Things: Image Parsing with Regions and Per-Exemplar Detectors," CVPR, 2013. (PDF) (Sup) (Poster) (Code) | |
Sift Flow Dataset:Output for our entire testset: Web |
LM+Sun Dataset:Output for our entire testset: WebFull Dataset |