
Posts by Collection
publications
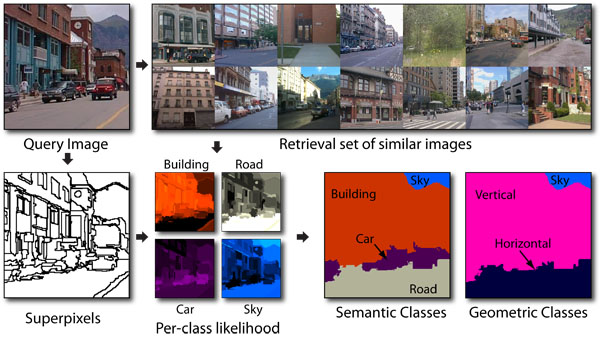
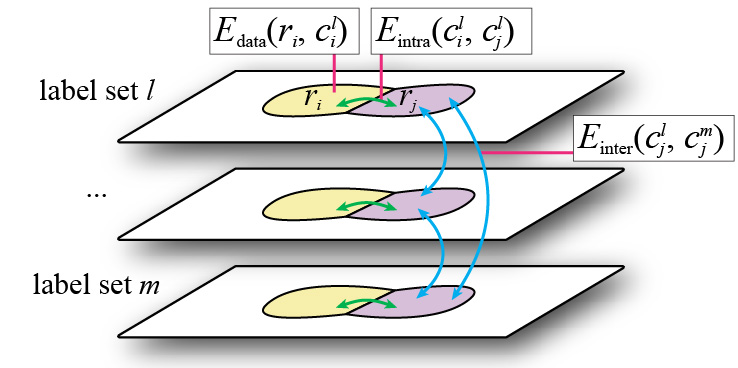


Combining semantic scene priors and haze removal for single image depth estimation Ke Wang, Enrique Dunn, Joseph Tighe, Jan-Michael Frahm, WACV 2014
[pdf]
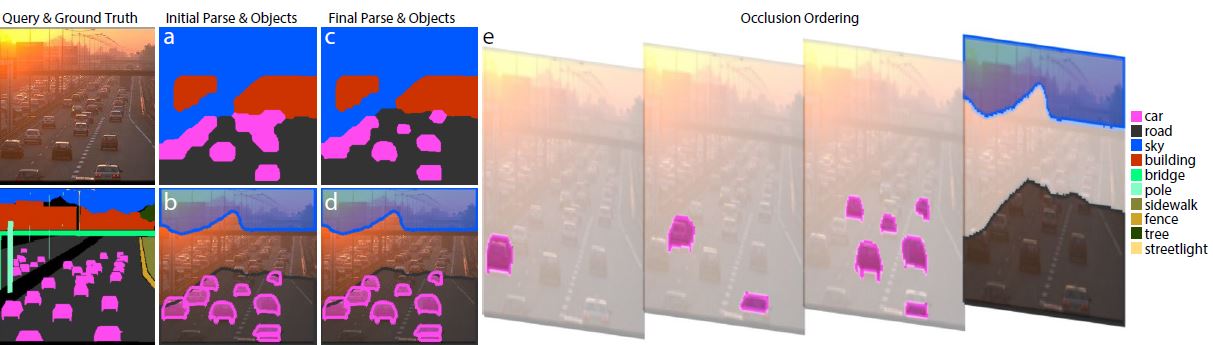

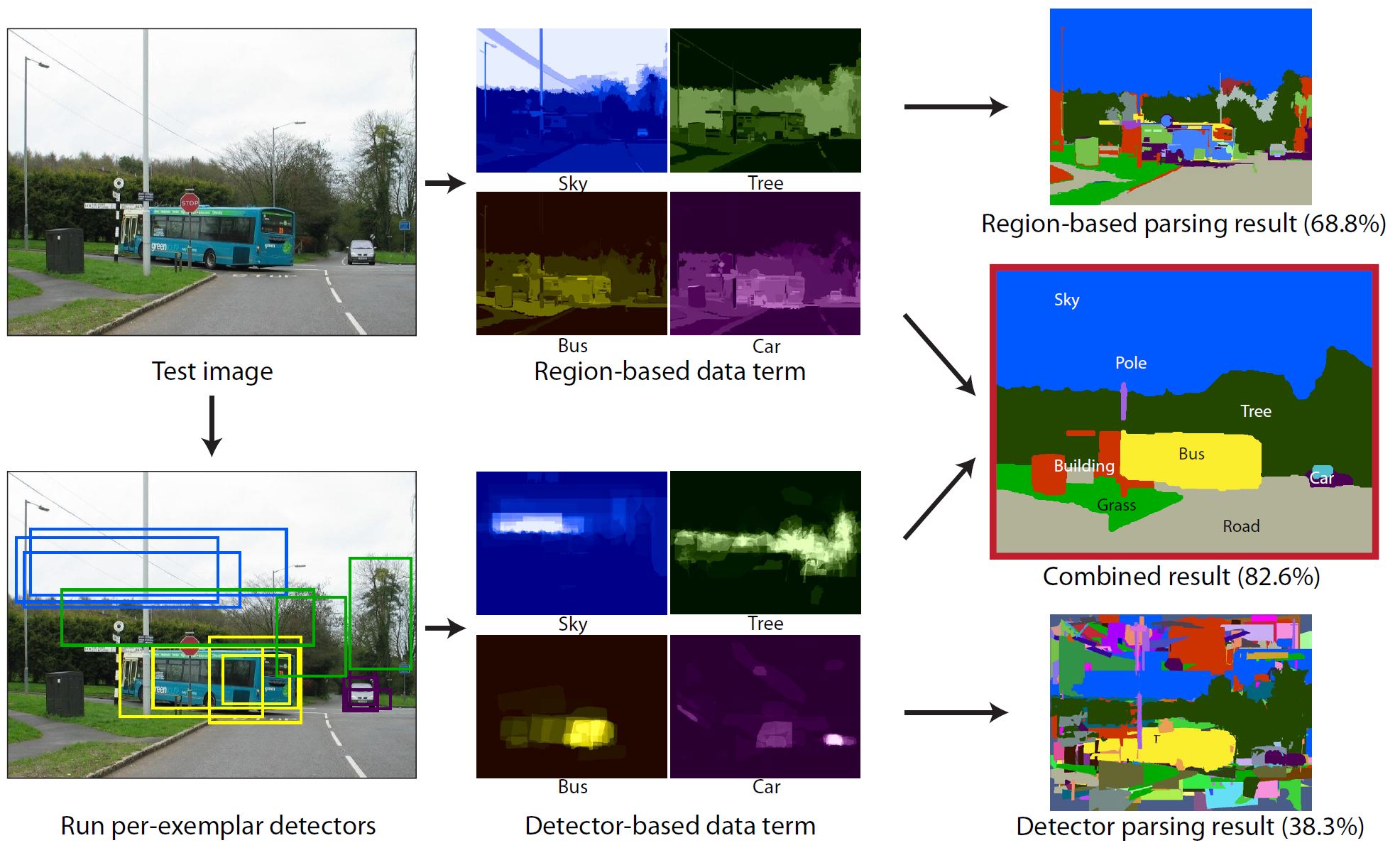
Scene parsing with object instance inference using regions and per-exemplar detectors Joseph Tighe, Marc Niethammer, Svetlana Lazebnik, IJCV 2014
[pdf]
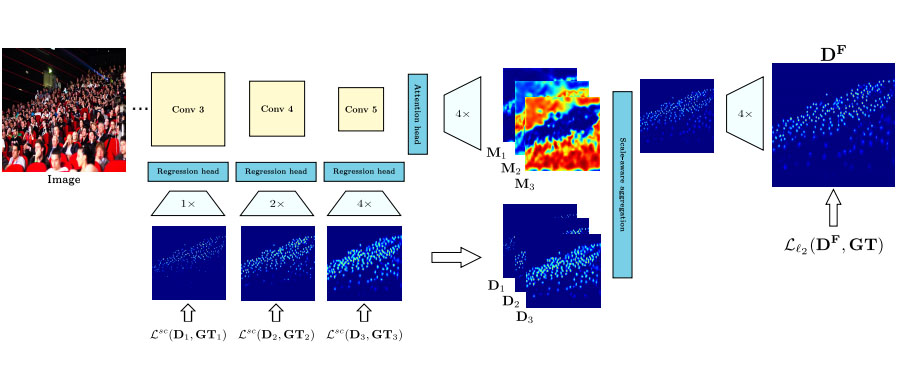
Scale-Aware Attention Network for Crowd Counting Rahul Rama Varior, Bing Shuai, Joseph Tighe, Davide Modolo, arXiv preprint 2019
[pdf]
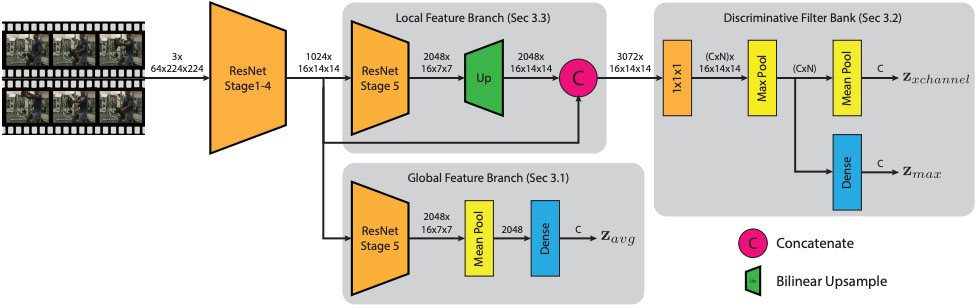
Action recognition with spatial-temporal discriminative filter banks Brais Martinez, Davide Modolo, Yuanjun Xiong, Joseph Tighe, ICCV 2019
[pdf]
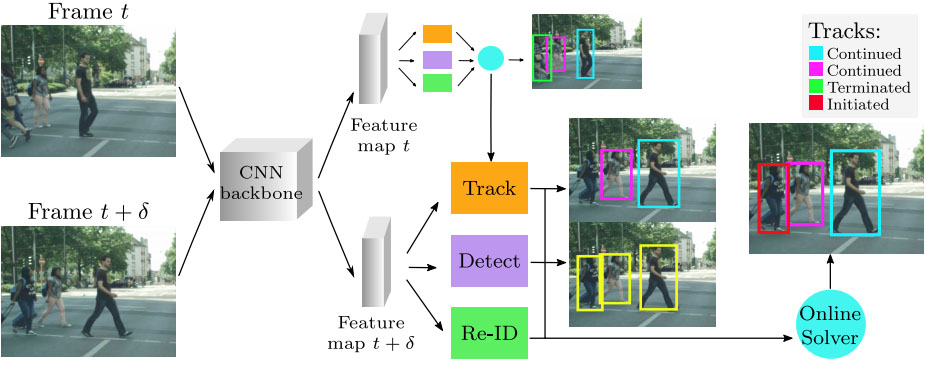
Multi-object tracking with siamese track-rcnn Bing Shuai, Andrew G Berneshawi, Davide Modolo, Joseph Tighe, arXiv preprint 2020
[pdf]
Application of Multi-Object Tracking with Siamese Track-RCNN to the Human in Events Dataset Bing Shuai, Andrew Berneshawi, Manchen Wang, Chunhui Liu, Davide Modolo, Xinyu Li, Joseph Tighe, ICM Workshop 2020 [pdf]
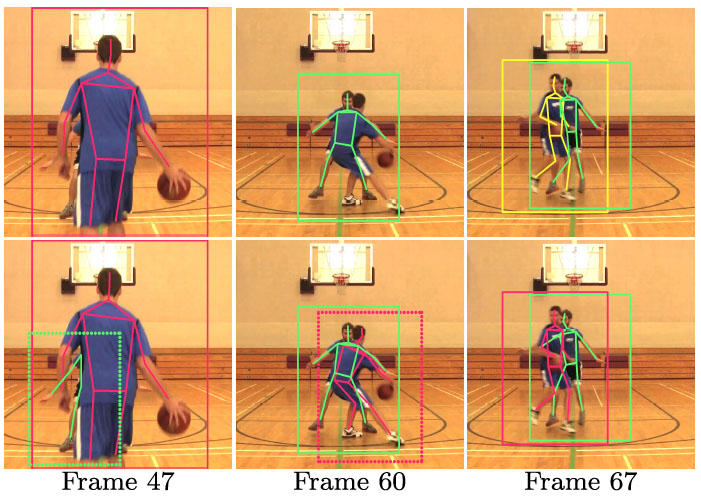
Combining detection and tracking for human pose estimation in videos Manchen Wang, Joseph Tighe, Davide Modolo, CVPR 2020
[pdf]
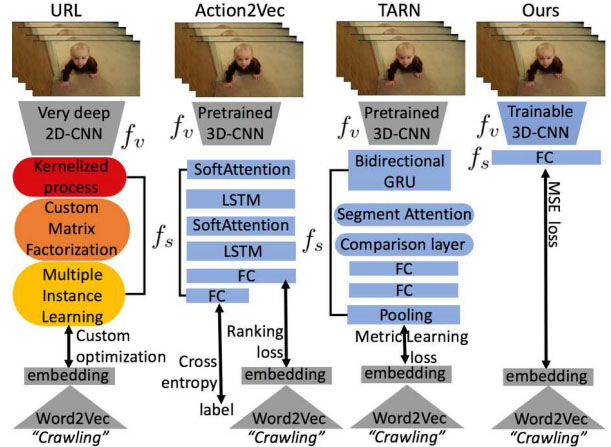
Rethinking zero-shot video classification: End-to-end training for realistic applications Biagio Brattoli, Joseph Tighe, Fedor Zhdanov, Pietro Perona, Krzysztof Chalupka, CVPR 2020
[pdf]
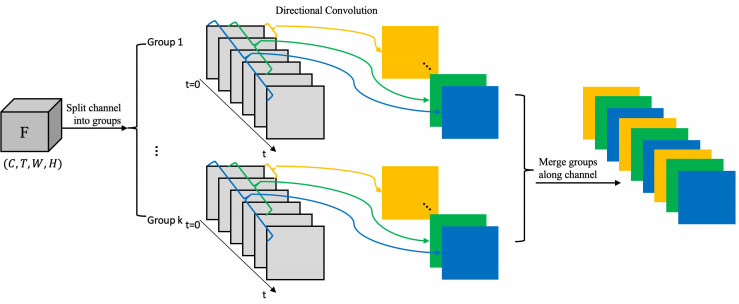
Directional temporal modeling for action recognition Xinyu Li, Bing Shuai, Joseph Tighe, ECCV 2020
[pdf]
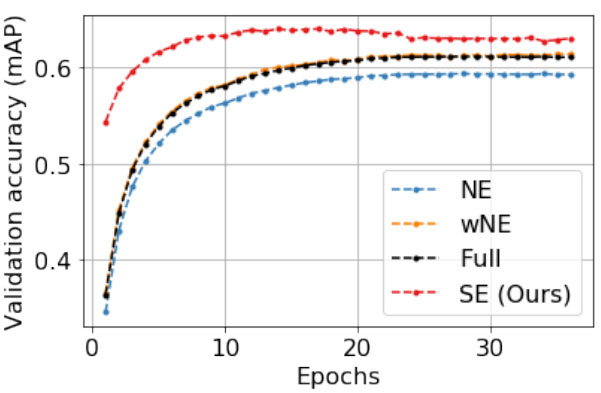
Exploiting weakly supervised visual patterns to learn from partial annotations Kaustav Kundu, Erhan Bas, Michael Lam, Hao Chen, Davide Modolo, Joseph Tighe, NeurIPS 2020
[pdf]
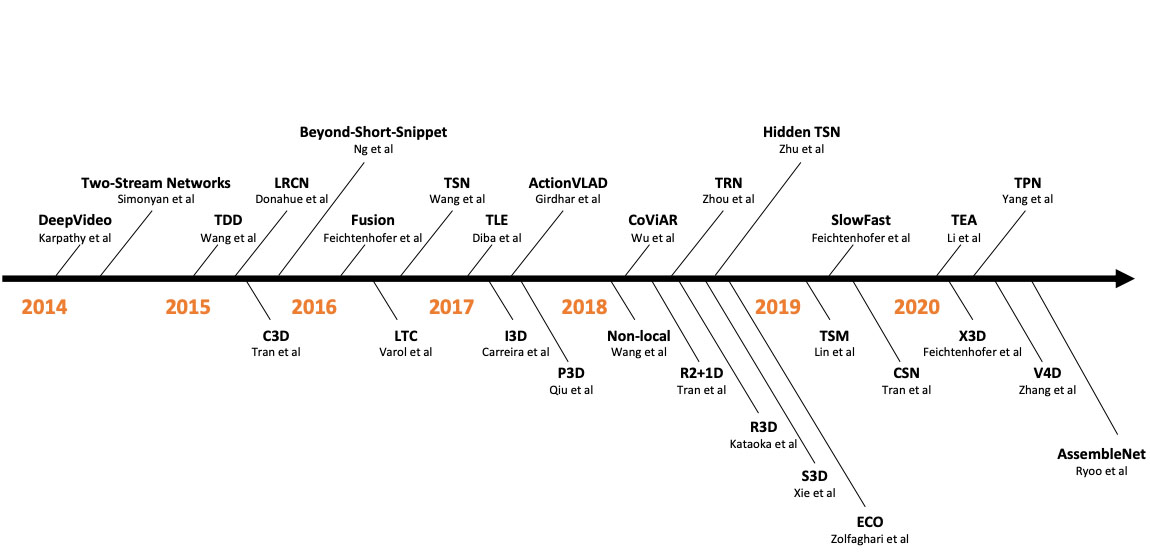
A comprehensive study of deep video action recognition Yi Zhu, Xinyu Li, Chunhui Liu, Mohammadreza Zolfaghari, Yuanjun Xiong, Chongruo Wu, Zhi Zhang, Joseph Tighe, R Manmatha, Mu Li, arXiv preprint 2020
[pdf]
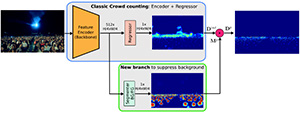
Understanding the impact of mistakes on background regions in crowd counting Davide Modolo, Bing Shuai, Rahul Rama Varior, Joseph Tighe, WACV 2021
[pdf]
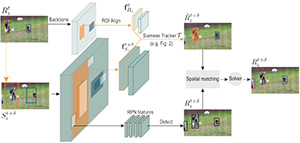
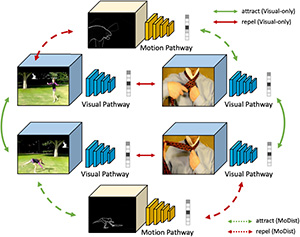
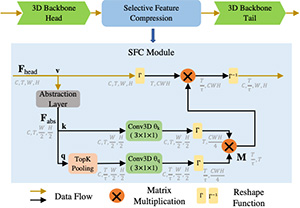
Selective Feature Compression for Efficient Activity Recognition Inference Chunhui Liu, Xinyu Li, Hao Chen, Davide Modolo, Joseph Tighe, ICCV 2021
[pdf]

Single View Physical Distance Estimation using Human Pose Xiaohan Fei, Henry Wang, Xiangyu Zeng, Lin Lee Cheong, Meng Wang, Joseph Tighe, ICCV 2021
[pdf]
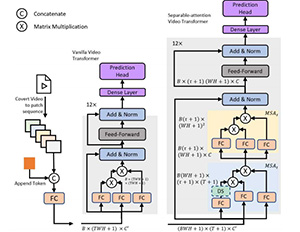
VidTr: Video Transformer Without Convolutions Xinyu Li, Yanyi Zhang, Chunhui Liu, Bing Shuai, Yi Zhu, Biagio Brattoli, Hao Chen, Ivan Marsic, Joseph Tighe, ICCV 2021
[pdf]
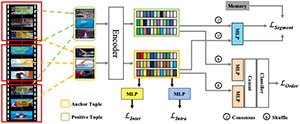
Video Contrastive Learning with Global Context Haofei Kuang, Yi Zhu, Zhi Zhang, Xinyu Li, Joseph Tighe, oren Schwertfeger, Cyrill Stachniss, Mu Li, ICCV workshop 2021
[pdf]
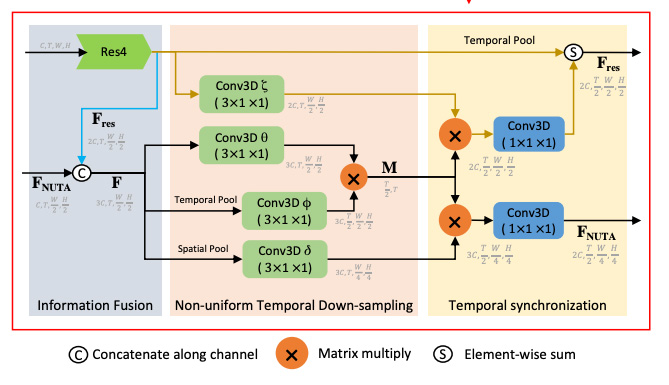
Nuta: Non-uniform temporal aggregation for action recognition Xinyu Li, Chunhui Liu, Bing Shuai, Yi Zhu, Hao Chen, Joseph Tighe, WACV 2022
[pdf]
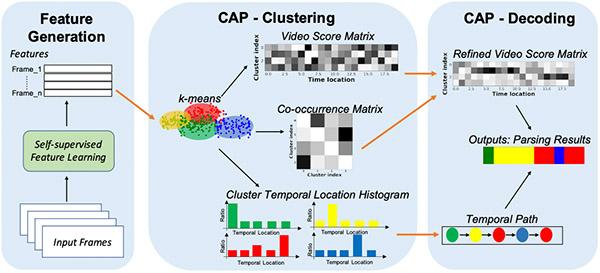
Sscap: Self-supervised co-occurrence action parsing for unsupervised temporal action segmentation Zhe Wang, Hao Chen, Xinyu Li, Chunhui Liu, Yuanjun Xiong, Joseph Tighe, Charless Fowlkes, WACV 2022
[pdf]
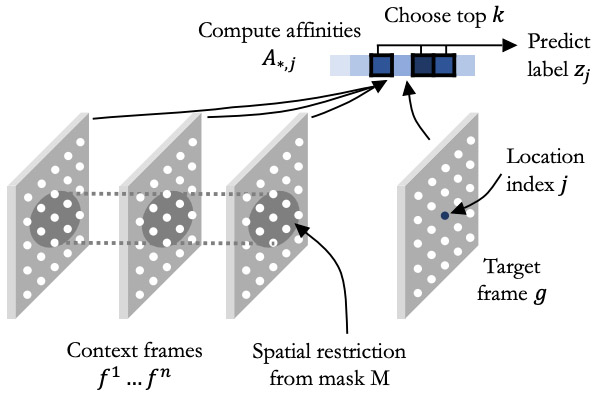
Transfer of Representations to Video Label Propagation: Implementation Factors Matter Daniel McKee, Zitong Zhan, Bing Shuai, Davide Modolo, Joseph Tighe, Svetlana Lazebnik, arXiv preprint 2022
[pdf]
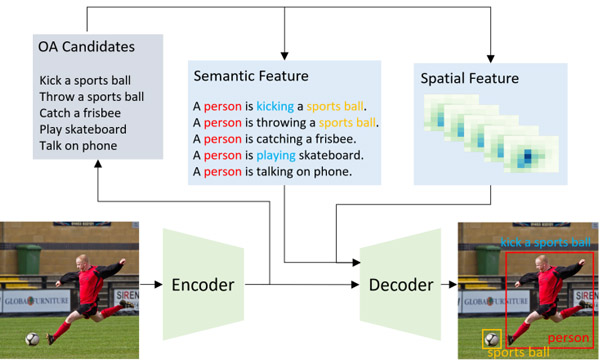
What to look at and where: Semantic and Spatial Refined Transformer for detecting human-object interactions ASM Iftekhar, Hao Chen, Kaustav Kundu, Xinyu Li, Joseph Tighe, Davide Modolo, CVPR Oral 2022
[pdf]
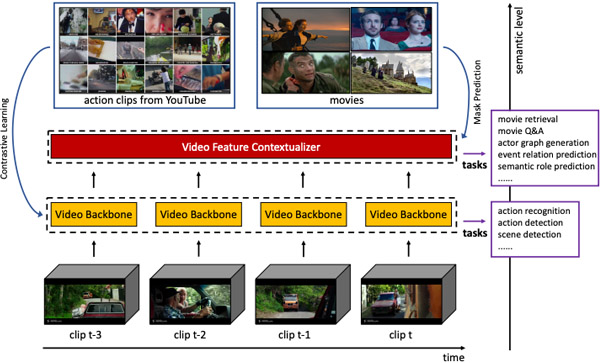
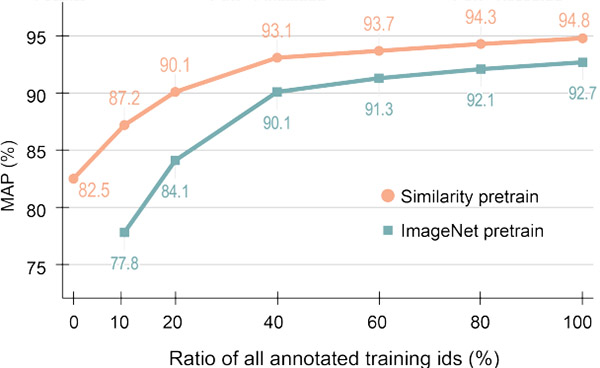
Id-free person similarity learning Bing Shuai, Xinyu Li, Kaustav Kundu, Joseph Tighe, CVPR 2022
[pdf]
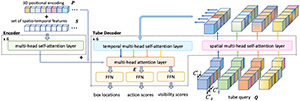
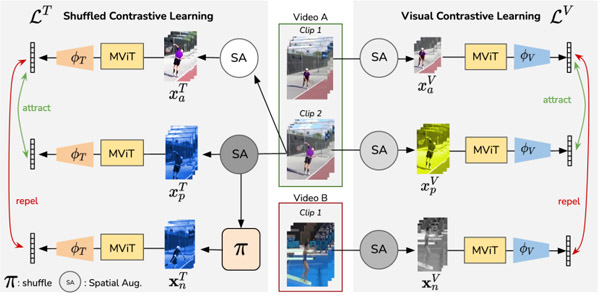
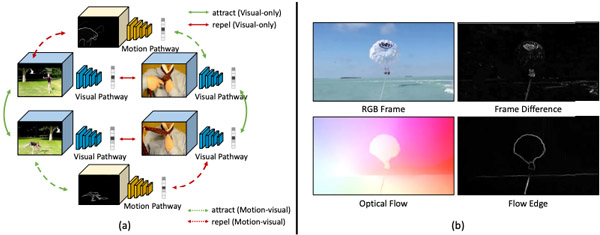
SCVRL: Shuffled Contrastive Video Representation Learning Michael Dorkenwald, Fanyi Xiao, Biagio Brattoli, Joseph Tighe, Davide Modolo, CVPR Workshop on Learning with Limited Labelled Data for Image and Video Understanding 2022
[pdf]
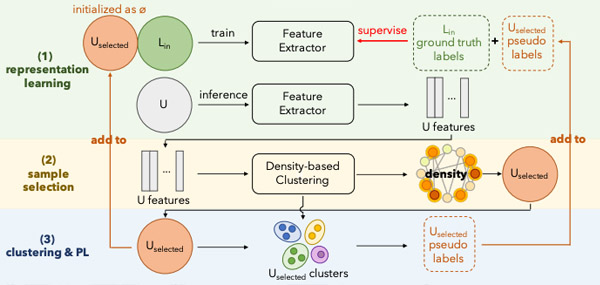
PSS: Progressive sample selection for open-world visual representation learning Tianyue Cao, Yongxin Wang, Yifan Xing, Tianjun Xiao, Tong He, Zheng Zhang, Hao Zhou, Joseph Tighe, ECCV 2022
[pdf]
